Data Modeling: Entities, Attributes, and Relationships
In the realm of information technology and database design, data modeling stands as a cornerstone, providing a systematic approach to representing and organizing data. It involves the creation of abstract models that depict the structure, relationships, and constraints of the data within a system.
Data Modeling
Is the process of transforming your business and application requirements into a blueprint and conceptual visual structure in order to create your actual database
We've touched upon a few concepts related to data modeling in our previous articles involving SQL examples. Let's delve into the fundamental aspects and understand its significance in the development of robust and efficient databases.
Key Concepts in Data Modeling:
1. Abstraction:
Data modeling involves simplifying complex real-world scenarios into abstract representations that capture essential aspects. These abstractions help in understanding and designing the data structure without getting bogged down by unnecessary details.
This is usually the requirements gathering phase and a discussion with stakeholders, product designers, and engineers etc on clarifying the details that are needed to design the database.
2. Entities and Attributes:
- An entity represents a distinct and meaningful object or concept in the real world. It can be a person, place, thing, event, or any item about which data needs to be stored.
- In a database, an entity is typically mapped to a table. Each row in the table represents a specific instance or occurrence of the entity.
Characteristics:
- Distinct Identity: Each entity should have a unique identity, and the data for that entity is stored in a table row.
- Properties: Entities have properties or attributes that describe their characteristics.
- Examples: In a university database, entities could include Student, Course, and Department.
Example:
Consider the entity "Student" in a university database:
Student Entity:
| StudentID | FirstName | LastName | Age |
|---|---|---|---|
| 1 | Alice | Johnson | 20 |
| 2 | Bob | Smith | 22 |
| 3 | Charlie | Brown | 21 |
In this example, each row represents a distinct student, and the columns (attributes) represent the properties of each student.
Attributes:
- Attributes are the properties or characteristics that describe entities. They provide details about the entities and are the building blocks of data within a database.
- Each attribute corresponds to a column in the entity's table, and it holds specific information related to the entity.
Characteristics:
- Descriptive: Attributes describe the features, qualities, or properties of an entity.
- Atomicity: Attributes should be atomic, meaning they cannot be divided into smaller components. For example, a "Full Name" attribute should be split into "First Name" and "Last Name."
- Data Types: Attributes have data types, such as integers, strings, dates, etc.
Example:
Continuing with the "Student" entity example:
Student Entity:
| StudentID | FirstName | LastName | Age |
|---|---|---|---|
| 1 | Alice | Johnson | 20 |
| 2 | Bob | Smith | 22 |
| 3 | Charlie | Brown | 21 |
In this case, the attributes include "StudentID," "FirstName," "LastName," and "Age." Each attribute holds specific information about the students, such as their identification number, first name, last name, and age.
3. Relationships:
- Relationships define how entities are related to each other. They represent the associations and connections between entities.
- Relationships are often represented as lines connecting entities, and they may have labels to indicate the nature of the relationship (e.g., one-to-many, one-to-one, many-to-many).
4. Constraints:
- Constraints: Define rules and limitations on the data. For example, a constraint might specify that a particular attribute cannot be null.
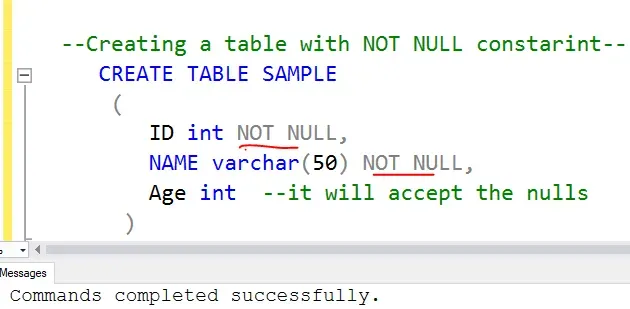
5. Diagrams:
- ER Diagrams (Entity-Relationship): Graphical representations of entities, attributes, and relationships.
- Cardinality describes the numerical relationship between entities in a relationship. It indicates how many instances of one entity are related to a single instance of another entity.
- Common cardinalities as previously discussed include one-to-one (1:1), one-to-many (1:N), and many-to-many (M:N) which can be seen in the visual representation in ER diagrams in most data model designs.
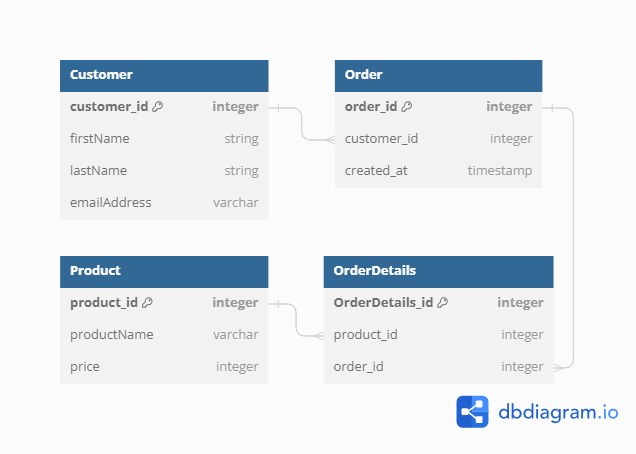
The Data Modeling Process:
1. Requirements Gathering:
Understand the information needs of the system and define the scope of the data model. Identify key entities, attributes, and relationships.
2. Conceptual Data Modeling:
Create a high-level, abstract representation of the data using tools like Entity-Relationship diagrams. This phase focuses on the essential structure and relationships without considering implementation details.
3. Logical Data Modeling:
Refine the conceptual model into a logical model that considers implementation details like data types, primary keys, and foreign keys. The logical model serves as a blueprint for the database and how we should create it.
4. Normalization:
Apply normalization techniques to ensure that the database is organized efficiently, minimizing redundancy and dependencies.
Normalization is an in-depth topic in itself which we may cover in a future article, but for now please check out this reference
5. Physical Data Modeling:
Translate the logical model into the actual database schema, considering specific database management system (DBMS) requirements. This phase involves defining tables, columns, indexes, and other implementation details and running the DDL SQL commands to create these structures.
Significance of Data Modeling:
- Clarity and Communication:
- Data models serve as a visual communication tool that helps stakeholders, including developers, designers, and business analysts, understand the structure and relationships within the data.
- Blueprint for Database Development:
- The data model provides a blueprint that guides the creation of the actual database. It ensures consistency and coherence in the way data is organized and accessed.
- Adaptability and Scalability:
- A well-designed data model allows for flexibility and scalability. As the system evolves, the data model can be adapted to accommodate new requirements without significant disruption.
- Data Quality and Consistency:
- By defining constraints and relationships, data modeling contributes to maintaining data quality and consistency. It helps prevent errors and ensures that the data accurately reflects the real-world scenario it represents.
- Efficient Querying:
- A well-structured data model supports efficient querying and retrieval of information. It enables the optimization of database performance by organizing data in a way that aligns with common access patterns.
Conclusion:
Whether creating a new database or enhancing an existing one, the principles of data modeling provide a roadmap for ensuring that information is not just stored but is structured and utilized effectively to support the goals of the organization.