SQL - Group By
The GROUP BY clause in SQL is a powerful feature that allows you to group rows based on the values in one or more columns. It is commonly used with aggregate functions to perform calculations on each group. Let's explore more advanced examples of the GROUP BY clause.
1. Grouping by Single or Multiple Columns:
Single Column
-- Mock data for Customers table
CREATE TABLE Customers (
CustomerID INT,
CustomerName VARCHAR(255),
Country VARCHAR(255),
City VARCHAR(255),
-- Other columns...
);
-- Inserting mock data
INSERT INTO Customers (CustomerID, CustomerName, Country, City)
VALUES
(1, 'Customer1', 'USA', 'New York'),
(2, 'Customer2', 'USA', 'Los Angeles'),
(3, 'Customer3', 'Canada', 'Toronto'),
(4, 'Customer4', 'Canada', 'Vancouver'),
(5, 'Customer5', 'Germany', 'Berlin'),
(6, 'Customer6', 'Germany', 'Munich'),
(7, 'Customer7', 'France', 'Paris'),
(8, 'Customer8', 'France', 'Marseille');
-- Query to generate result set by grouping only by Country
SELECT Country, COUNT(CustomerID) AS CustomerCount
FROM Customers
GROUP BY Country;
In this example, the query groups the "Customers" table by the "Country" column and calculates the count of customers for each country.
The result set, based on this mock data, might look like:
+---------+--------------+
| Country | CustomerCount|
+---------+--------------+
| USA | 2 |
| Canada | 2 |
| Germany | 2 |
| France | 2 |
+---------+--------------+
This shows the count of customers for each unique country in the "Customers" table.
If we ran the Count of Customers without the GROUP BY clause, we would just retrieve the total number of customers as one result set row.
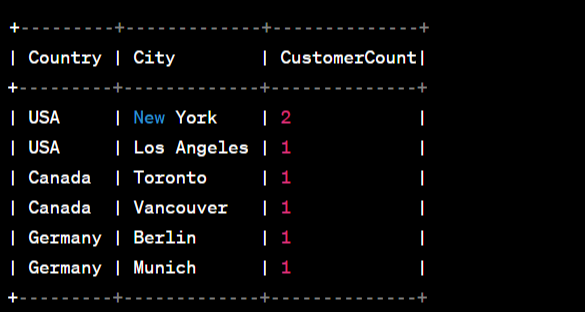
Grouping by Multiple Columns
Depending on how your data is structured, you can use the GROUP BY clause with multiple columns to create more specific groups.
SELECT Country, City, COUNT(CustomerID) AS CustomerCount
FROM Customers
GROUP BY Country, City;
In this example, the Customers table is grouped by both "Country" and "City." The COUNT function then calculates the number of customers in each specific country and city combination.
So our result may look something like this:
2. Using Aggregate Functions:
Combine GROUP BY with various aggregate functions to derive insights from grouped data.
SELECT DepartmentID, AVG(Salary) AS AvgSalary, MAX(Salary) AS MaxSalary
FROM Employees
GROUP BY DepartmentID;
This query calculates the average and maximum salary for each department in the "Employees" table and groups it by each Department.
3. Filtering Grouped Data:
Apply filtering conditions to the grouped data using the HAVING clause.
SELECT CategoryID, AVG(Price) AS AvgPrice
FROM Products
GROUP BY CategoryID
HAVING AVG(Price) > 100;
Here, the HAVING clause is used to filter the result set and include only those categories with an average product price greater than 100.
4. Grouping by Expressions:
You can also group data based on expressions or derived columns.
SELECT YEAR(OrderDate) AS OrderYear, COUNT(OrderID) AS OrderCount
FROM Orders
GROUP BY YEAR(OrderDate);
This query groups orders by the year extracted from the "OrderDate" column, providing a yearly summary of order counts.
Conclusion:
The GROUP BY clause in SQL is a versatile tool that allows you to analyze and summarize data in a more granular way. By combining it with aggregate functions, expressions, you can gain deeper insights into your dataset, making it an essential component for complex data analysis in relational databases.